有哪些优化指标
项目的优化直接影响着应用的使用体验。首先我们需要选择一些指标来作为优化目标:
- 运行时指标:帧率FPS是我们最常接触,也是体验最明显的性能指标。一个项目15帧基本上是不能用的状态,30帧勉强能用,能做到60帧则会让用户体验有极大的提高。另一方面,运行时内存大小也十分重要,考虑到移动平台内存条件有限,过大的内存占用很容易造成杀后台和进程崩溃。
- 离线指标:Unity为了尽可能适配所有类型的资产,提供了丰富繁杂的资产导入设置。然而为了普适性,其中很多默认设置存在性能、存储大小、内存大小等方面的浪费,因此如何优化好一个资产的离线设置也对项目很有帮助。另一方面,减小包体大小对于项目的分发也有所帮助,毕竟没有人愿意动不动就下1G的APP。
下面从离线资产优化开始介绍。
离线资产优化
欲先行其事,必先利其器。如果你没有丰富的开发经验,很难去判断一个资产设置的合不合理,而且人工检查资产也费时费力。因此这里推荐自动化的资产检查工具UPR AssetChecker
常见资产优化
音频设置优化:一般我们下载到的原始音频资源都是无损的wav格式,因此体积较大。然而在绝大部分情况下,我们的APP不需要高精度的音频质量,并且可以做一些针对性的格式修改:
- 立体声转为单声道:一些以Player为中心播放的音频其实不存在立体声的效果,因此可以把立体声通道去除,强制转为单声道音频。
- 压缩格式:wav保留了最完整的音频细节但是体积巨大,因此我们可以选择Ogg或者Mp3格式,在保留90%的细节同时极大的压缩文件体积。
- 音频采样率:通常电脑端的音频都是44K采样率,然而对于手机有限的处理性能和音响性能来说,44K通常是不必要的,改为22K能在不怎么影响音质的同时缩小一半的音频体积。 [图片]
3D模型设置优化:
- Mesh Compression 设置压缩格式。
- Read/Write 如果运行时需要修改网格才开启,开启后会在CPU内存中产生一份模型内存(本来仅在GPU中)。
- 不必要的Rig、Animation、Material mode、法线等可以关闭
- Animation Type:Humanoid比Generic性能差30%,但提供Kinematices和Retargeting功能。
- Index Format 如果顶点数小于65535,可以用16位的索引。
- Player Settings中优化选项:Vertex Compression、Optimize Mesh Data
纹理设置:
- 设置压缩格式
- Read/Write 用于脚本Texture2D接口访问纹理,开启会产生纹理的CPU拷贝。
- Mipmap 开启会产生1/3的额外内存
- 重复纹理检测
- 注意单色纹理设置为单色格式
- 检查图集空间利用率,打包合适的图集。
参考
运行时性能优化
指标检测工具:
- 帧率分析工具 Unity Profiler
- 内存分析工具 Memory Profiler
Unity API注意事项
Gameobject.Find(“something”):这是一个写起来很方面,但是效率很低的API。它会在整个场景中搜索所有的对象进行匹配。想一下每次要在100000个阀门里找一个名字叫“FMAABB”的阀门。因此尽量不要使用Gameobject.Find。绝大部分Find都可以通过编辑器的预置序列化来实现,实在不行还能使用FindWithTag来替代。- 生命周期函数:尝试自己接管各个MonoBehaviour的回调如Update。Unity管理回调时是通过native层跟踪并唤醒C#层的Update方法,因此会存在两层之间的通信开销。即使是空的Update(){}也一样有开销。因此可以尝试不走MonoBehaviour的结构,定义一个普通的C#类和Update方法,并由自己的UpdateManager类来调用它们的Update。 >UpdateManager可以用委托+观察者模式来实现,但要小心C#委托在添加或移除订阅者时,会完全复制整套订阅者,和string一样。
- Null比较:减少UnityEngine.Object派生类的Null比较,因为这实际上会变成native code层的比较,比常规的C#对象慢。
- 组件属性设置:尽量使用Hash
ID:例如Animator的
SetFloat(string name),本质上会使用Animator.StringToHash把name转为int id,然后在Unity内部进行属性索引。因此我们可以手动计算好Hash ID,然后取调用SetFloat(int ID); - CullingGroup:可以用来hook物体的可见性和LOD层次更新,以便看情况关闭不可见对象的相关脚本。
- 没有内联优化:Unity编译流程基本不会对C#函数做内联优化,因此可以考虑手动内联简单函数。
- 小心array的复制:Unity中大部分返回array的API都是复制,因此注意不要重复调用访问器,如下:
>以下代码会生成3份vertices。 > >
1
2
3>x = mesh.vertices[i].x;
>y = mesh.vertices[i].y;
>z = mesh.vertices[i].z;
UGUI
UI面板看起来很简单,但实际上也是性能消耗的一个大头:
小心透明通道:UGUI所有组件都是在透明通道绘制:有时候我们会偷懒没有关闭旧的UI,而直接把新的UI覆盖在了上面。然而由于UGUI是在透明通道,被挡住的UI依然会进行渲染操作,浪费性能。
减少UI输入事件的检查:在接受到输入信号如点击、拖动时,UGUI会遍历整个屏幕上所有的可交互UI对象,并检查它们的位置是否在输入信号的位置。类似于Gameobject.Find,整个遍历操作也是浪费性能的,因此对于不需要交互的UI组件,我们应该关闭Raycast Target或Interactable选项,减少遍历对象。
减少自动布局频率: Layout或AutoSize能够方便地实现自动布局,但是这些布局是要Unity通过CPU算出来的,每次对UI的相关改动都会导致layout的rebuild。
另外特别注意TMP的AutoSize功能,其通过遍历迭代多个size来找到最合适的字体大小,效率极低,尽可能少用并且避免频繁更新autosize的TMP组件。参考
动静分离:如果每个UI元素都独立一次drawcall的话,那显然会极大浪费渲染队列,因此UGUI在绘制UI时会将UI元素进行网格合并的操作,以尽量一次Drawcall绘制。
合并的出发点没有问题,但因此只要任何一个UI元素一变,网格就需要重新合并,这样节省下来的drawcall cpu占用全用在合并顶点上了。因此,为了减少网格的重新合并,需要UI元素的动静分离。UGUI中以Canvas为合并网格的基础,因此我们需要尽可能把动态UI元素放在单独的Canvas中,把静止常态的UI放在另一个Canvas中。
嵌套子Canvas也不会和父Canvas合并
重UI的分解:随着UI嵌套的越来越厚、越来越多,项目后期的一个UI对象可能会套着好几层UI面板,并且用的时候只显示某一个,隐藏其他的。因此虽然看起来没什么,但在对这个重UI实例化和销毁的时候会变得很慢,因此可以考虑把不必要的二级UI拆分成单独的对象,在需要时才实例化生成,而不是激活和隐藏。
不管分不分解,加载这些对象的CPU时间都是需要的,但本质上我们把集中的大段CPU作业拆解成了多个小段,以降低卡顿。当然,也要注意如果拆分不当,导致小元素频繁实例化和销毁也会造成性能浪费。
加载优化:UI加载并实例化需要做完:加载GameObject对象、网格合并、组件初始化、素材资源加载等任务,并不算轻松。因此可以考虑在CPU缓和的情况下预加载UI:例如提前加载AB包素材。或者像上一节中对UI进行激活和隐藏处理,而不是生成和销毁。激活和隐藏不用再改变内存,但是组件的重新enable也会带来一定开销,因此再极端一点可以考虑直接把UI移出屏幕并且关闭部分更新,以形成隐藏。
字体拆分:字体图集也是一项比较重的资源,而UI中如果同时有几种不同的字体,也会对内存造成一定负担。因此可以针对于特定使用场景,提取出特定词汇单独生成一个字体图集使用,比较常见的有登录场景字体、数值字体、常用字字体。
渲染优化
除去渲染算法上的改动,我们能在渲染上做的优化大致分为两类:
- 渲染剔除:减少渲染对象。
- 渲染合批:减少CPU drawcall和GPU状态改变。
渲染剔除
由于玩家视野有限,很多物体即使渲染出来玩家也根本看不到,是白白浪费性能。因此可以尽量减少玩家视野之外的物体渲染,来减轻GPU压力:
- 相机视椎体剔除:这一点Unity已经默认做了。但是我们依然能够根据玩家所处场景,去动态修改相机视椎体大小,比如在房间内时使视椎体更小一点,充分发挥视椎体剔除的作用。
- Camera的Layer Mask和Layer Distance:根据情况,我们可以定制Camera渲染的层级。同样例如在房间内,可以只显示InHouse Layer。而Layer Distance则可以用来定制每个Layer的剔除距离,覆盖视椎体远平面的剔除。
- LOD:根据玩家距离,动态决定物体网格细节,以便节省一些不必要的模型顶点数和面数。推荐一个简单易上手的插件NanoLOD
- 遮挡剔除:如果一个物体被挡在其他物体后面完全看不到,我们也没必要去渲染它。不过需要CPU去判断物体的遮挡关系,因此实际上是用CPU换GPU
- 像素剔除:即使渲染物体数不变,我们也可以从shader上挤出一些像素剔除来节省shader计算,例如选择是否开启背面剔除、Early Z。
另外从更宏观的层面上,如果场景灯光数过多,会造成前向渲染的压力,可以考虑改成延迟渲染或者Forward+。
渲染合批
由于GPU是状态机模式运行,并且CPU和GPU中间存在着通信交换的开销,因此在渲染物体不变的情况下,减少CPU和GPU的drawcall通信,减少GPU状态的切换,也能够有效提升性能。(通常是节省CPU的时间)
一方面我们可以对资源提前做好合批:
- 网格合批:使用C# CombineMesh或者3D软件提前将进行网格层次的合并。
- 纹理合批:使用Sprite Atlas和TextureArray对纹理进行打包管理。
- Shader属性合批:使用Material Property Block对同材质但有不同属性的大量物体进行属性修改。
另一方面,Unity也提供了一些运行时渲染合批的方法:
- 静态合批:对于标记为Static的物体都可以参与到静态合批中。不过需要一批最多顶点数为64000,并且合并后的超大网格也会影响到一些剔除判定。
- 动态合批:对任何对象,Unity都可以提供运行时动态合批,但这需要消耗CPU即时计算,不一定会带来性能提升。并且限制条件也很多。 >静态合批和动态合批都会额外生成一份合并网格,导致网格内存占用翻倍。
- 其他运行时合批技术:SRP Batching、GPU instance
资源加载优化
另外一个很影响使用体验的点就是资源加载。一方面不合理的资源加载会导致读屏时间过长,另一方面不当的内存资源管理也会导致内存的浪费。
举个例子:默认情况下,我们会把一个重复使用的模型做成Prefab资源,然后在其他代码中引用并Instantiate实例使用。然而在Instantiate之前,实际上由于Prefab的引用,我们会在APP启动时将prefab先加载到内存,之后再等待Instantiate。这样会造成启动加载时间过长,以及Instantiate之前不必要的内存占用。
常见的导致启动时加载资源的原因有三类:
- 场景预置资源:例如已经把房子、树木等摆在场景中了。那么在启动加载场景时,必须要先把房子、树木的纹理和模型等资源加载进入内存。
- C#序列化引用:例如我们平常引用的public Gameobject,如果上述的场景预置资源A上挂了一些代码,并且代码引用了一些其他资源B,那么B也会跟随A在启动时加载。
- Resources文件夹:所有放在Resources文件夹的资源都会在启动时加载。Unity建议不要使用Resources文件夹。
那么我们应该怎么改造资源加载呢?推荐使用AssetBundle/Addressable对资源进行按需加载。其中Addressable是对AssetBundle封装后更简洁易用的API。
AI寻路优化
寻路算法中最经典的就是A星算法。虽然经典的最短路径算法有Dijkstra和Floyd,但是其复杂度分别是O(N2)和O(N3),空间复杂度都是O(N^2),因此根本不适合游戏这种大型路径搜索需求。并且更重要的一点是,游戏寻路根本不在乎是不是最短路径,只需要是一条能走通的路径就行,这就是A星算法的根本目标,其使用贪心算法寻找局部优解来寻路,平均时间复杂度为O(N logN)。然而,A星的具体实现中还有很多细节可以优化。
大场景分割
假如游戏场景很大,那么贪心搜索空间就会十分庞大,我们需要尽可能缩小搜索范围。回头想想,之所以我们要启用寻路算法,是因为出发点和目标点之间存在障碍物,不能直线到达。然而在大场景中,大部分路径是可以直接到达的,并不需要费劲寻路。
因此,我们可以把大场景分割成数个内部无障碍的区域。在区域内部,可以直接直线寻路。在区域外部,则是一个区域与区域之间的固定寻路 (从区域A到区域B,我们只需要提供一条固定路线即可)。而寻路既然已经不是动态的,那我们可以离线计算寻路路径,存储给实时使用,极大节省实时效率。
当然,区域外部一旦发生改变,这些离线结果都需要重新计算。
堆存储openlist节点
在贪心搜索局部最优解时,我们需要维护一个排序列表来方便获得最优节点 (最小损失的节点)。我们要么在每次插入新openlist节点时有序插入,要么每次确定最优节点时先排一次序。排序本身就是一件很慢的\(NlogN\)行为,因此不可能每次都排序。而如果是有序插入,例如二分查找插入点插入,那么需要\(log N\)的查找时间以及\(N\) 的数组移动时间。 为了避开数组移动的麻烦,同时保持有序插入的便捷,我们可以使用最小堆/优先队列来维护openlist节点列表,这样我们只有\(logN\)的插入时间,而不需要移动原数据。
openlist搜索规则优化 JPS
贪心的一个问题在于它是一步一个脚印去走的,因此即使是从(0,0)到(0,50)这样的直线路径,也会存储至少50个寻路节点,并且消耗50次插入时间,以及openlist空间包含这50个节点的所有邻居。那我们是不是能简化这种直线路径呢?
跳点算法 Jump Point Search (JPS) 框架上还是A星的框架,同样是搜索节点,加入openlist,从openlist中取出最优节点寻路。JPS主要改动在于它的搜索节点策略,它不像贪心一样每一步都将所有邻居加入openlist。JPS只在openlist记录那些关键的跳点节点,也就是直线的拐点,而对于平常的直线路径节点则不记录。
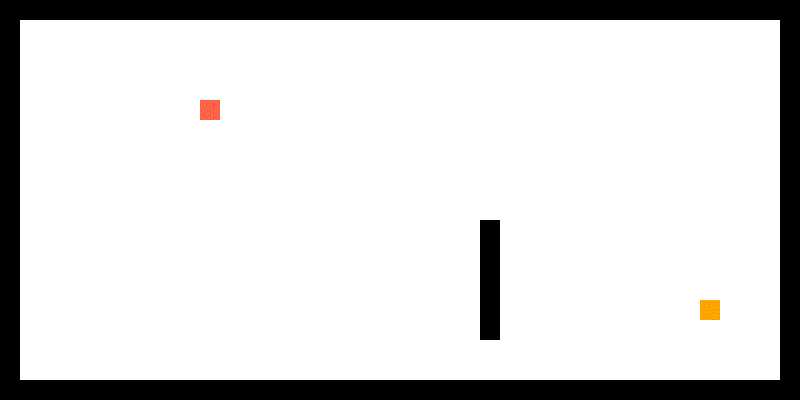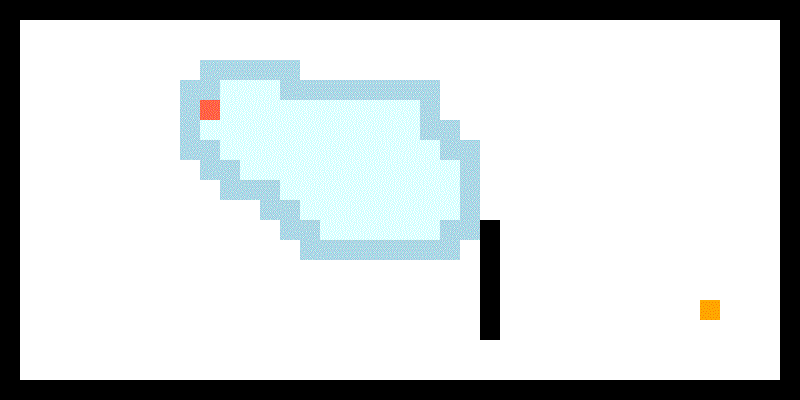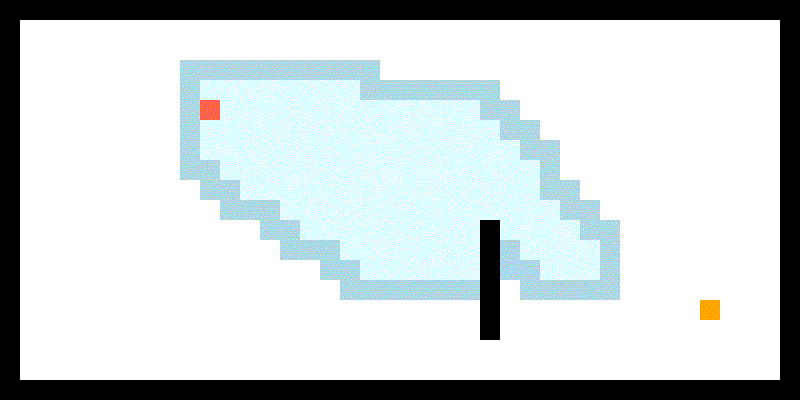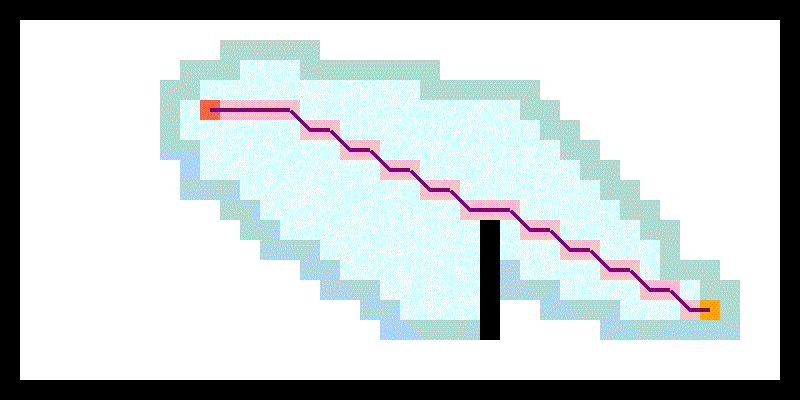
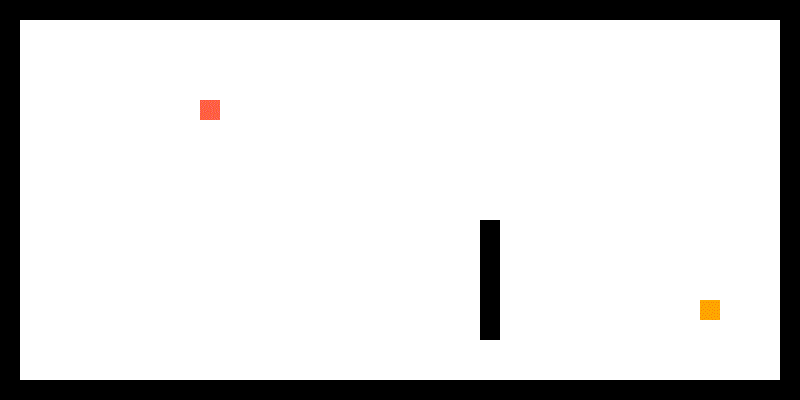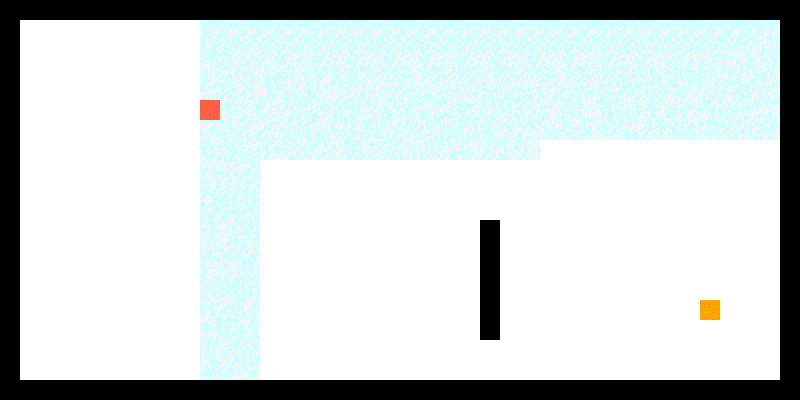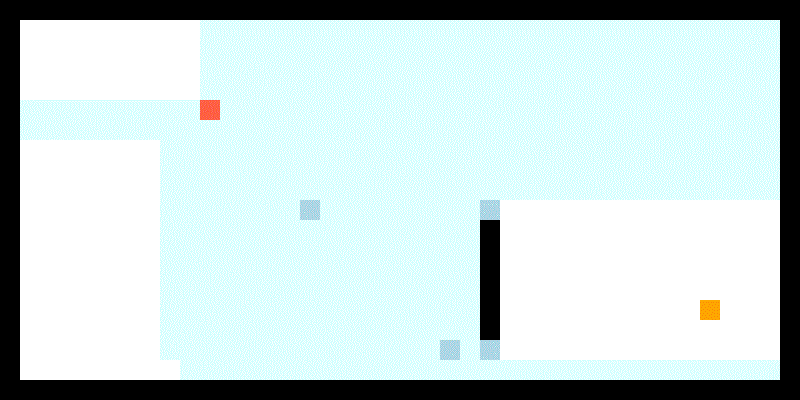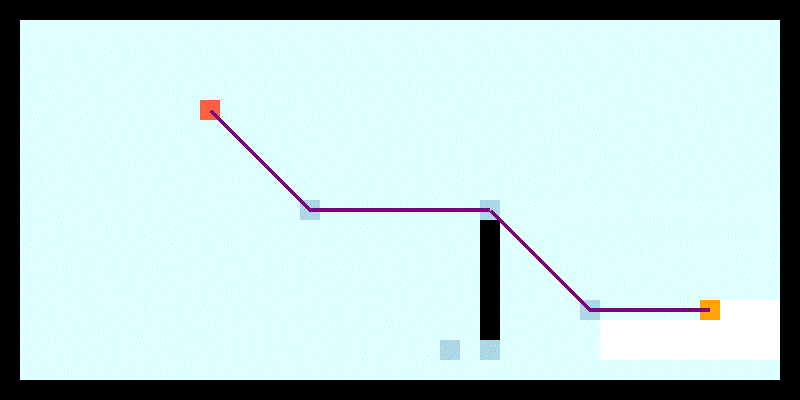
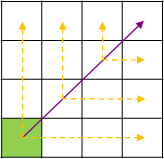
JPS具体规则较为复杂,可以参考上文链接,这里简单概括下两个主要思路:
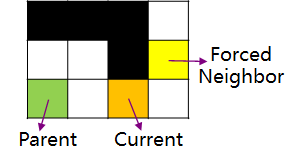
一,检查当前节点是否是跳点。简而言之,跳点就是发生拐弯的节点。那么什么时候会发生拐弯呢?如下图,我们从绿色父节点A出发,一路沿途检查节点是否为跳点 (沿什么途则在后文),经过若干次检查后,我们开始检查橙色节点B。我们首先知道B有一个邻居黄色节点C,且B和C中间有障碍物。此时我们检查A到C的最短路径,发现必须要经过B节点拐弯去C点,这时候B就是C的跳点,C就是B的强迫邻居(forced neighbor),并且我们可以把B加入openlist。
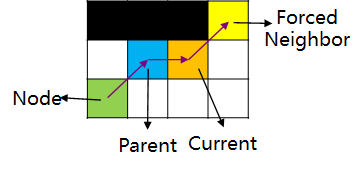
同样,假如A到跳点B中间本身就需要在D点拐一次弯(即A与B非直线可达,D与B直线可达),那么D也是跳点。注意这里要求B是跳点,D才是跳点,要不然这个拐弯就没有意义了是不是。
因此整个跳点检查有点类似于栈模式,先确定最后一个跳点,然后才能认为之前的拐点是跳点。
二,往什么方向搜索跳点。现在我们知道了怎么检查一个点是否是跳点,但是去检查哪些点呢?由于JPS只关心直线走到尽头后的拐弯点,因此基本原则是先以直线方向一路检查是否为跳点,结束后再斜向进一步搜索内圈。具体细节则可另外搜索。